1. Cognitive Science 인지과학
1.1 AI Artificial Inteligence 인공지능이란?
인공지능은 일반적으로 인간의 지능이 필요하거나 인간이 분석할 수 있는 것보다 규모가 큰 데이터를 포함하는 방식으로 추론, 학습 및 행동할 수 있는 컴퓨터 및 기계를 구축하는 것과 관련된 과학 분야
AI는 컴퓨터 공학, 데이터 분석 및 통계, 하드웨어 및 소프트웨어 엔지니어링, 언어학, 신경 과학은 물론 철학과 심리학을 포함하여 여러 학문을 포괄하는 광범위한 분야임
1.1.1 인공지능 종류
(1) NLP Natural Language Processing 자연어 처리
: 머신러닝을 사용하여 텍스트와 데이터를 처리하고 해석함
(2) SST/TTS Speech To Text / Text To Speech
인간이 특정분야에 대하여 가지고 있는 전문적인 지식을 정리하고 표현하여 컴퓨터에 기억시킴으로써, 일반인도 이 전문지식을 이용할 수 있도록 하는 시스템
(3) Expert&Systems : 전문가 시스템
(4) planning Scheduling&Optimization
(5) Robotics 로봇공학
(6) Vision
컴퓨터 비전은 인공지능(AI)의 한 분야로, 컴퓨터와 시스템을 통해 디지털 이미지, 비디오 및 기타 시각적 입력에서 의미 있는 정보를 추출한 다음 이러한 정보를 바탕으로 작업을 실행하고 추천할 수 있도록 함
1.2 ML Machine Learning 머신러닝(기계학습)
머신러닝은 인공지능에 포함되는 한 분야로, 많은 양의 데이터를 제공하여 명시적으로 프로그래밍하지 않고 신경망과 딥 러닝을 사용하여 시스템이 자율적으로 학습하고 개선할 수 있게 해줌
1.2.1 ML 종류
(1) K-means k-means algorithm
(2) Naïve-Bayes 나이브 베이즈 분류 (classification)
(3) ANN Artificial Neural Network 인공신경망
사람의 뇌 속 뉴런의 작용을 본떠 패턴을 구성한 컴퓨팅 시스템
(4) Decision Tree 의사 결정 트리
(5) Random Forrest
분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종
(6) SVM Support Vector Machine 서포트 벡터 머신
기계 학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도 학습 모델
(7) K-nearest neighbor
1.3 DL Deep Learning 딥러닝이란?
deep learning 기계학습 종류 중 하나인 인공신경망(ANN) 방법론 중 하나로, 인간의 두뇌에서 영감을 얻은 방식으로 데이터를 처리하도록 컴퓨터를 가르치는 인공 지능(AI) 방식
1.3.1 DL 종류
(1) CNN Convolutional neural network 컨볼루션 신경망
데이터로부터 직접 학습하는 딥러닝의 신경망 아키텍처
(2) RNN Recurrent Neural Network 순환 신경망
시계열 또는 순차 데이터를 예측하는 딥러닝을 위한 신경망 아키텍처
(3) GAN Generative Adversarial Networks 적대적 신경 생성망
실제에 가까운 이미지나 사람이 쓴 것과 같은 글 등 여러 가짜 데이터들을 생성하는 모델입니다.

2. ANN vs DNN
1. ANN
인공 신경망(Artificial Neural Network, ANN)은 사람의 뇌 속 뉴런의 작용을 본떠 패턴을 구성한 컴퓨팅 시스템

↓


2.DNN

3. AI 가 성공할 수 있었던 이유
(1) Computing Power
강력한 병렬 및 분산처리 능력 ex) GPU by NVIDIA
->계산이 빠르다 ex)연립방적식 부등식등 을 그래프로 풀 수 있는 유닛
(2) Big Data Power
인터넷, IOT(요즘은 IOE라고도 함), Sensor 기술을 통한 수집 능력
(3) 공개 소프트 웨어
개방·공유·협업의 성과
4. 각 분야가 빅데이터, 인공지능을 만나면?
(1) 빅데이터, 인공지능을 이용한 신약개발
(2) 빅데이터를 이용한 스포츠
ex1)야구선수의 출루율 계산을 이용한 팀 구성
ex2)각 선수의 순간 가속도, 이동 속도, 볼 접촉 기록을 모아 선수 개개인의 약점을 보완하는 훈련 및 팀 훈련 효율을 높이는 전략을 찾아냄
(3) 인공지능을 이용한 요리
(4)빅데이터를 이용한 범죄
5. 은행에서의 빅데이터 (Big Data in banking) - connect data, find new business
5.1 금융 빅데이터 트렌드
3차 산업혁명 '자동화' 시대에서 4차 산업혁명 '지능화' 시대로 넘어가기 위해 모든 산업이 변화하고 있으며, 이에 대한 빅데이터 기반의 소프트 파워 역략을 갖추는 것이 중요하게 됨.


6. 빅데이터 발전 4단계 : big value 찾기

(1) 묘사 분석 : 어떤 일이 일어났는가?
(2) 진단 분석 : 왜 일어났는가?
(3) 예측 분석 : 무슨 일이 일어날 것인가?
(4) 처방 분석 : 우리는 무엇을 해야할 것인가?
7.one view one voice(Omni-channel)
"Trace Customer Behaviors"
CRM -> CEM
CRM : Customer Relationship Management 고객 관계 관리 고객, 특히 회원 가입의 과정을 거쳐서 리스트를 가진 구매자(즉, 소비자나 일회성 구매자 보다는 지속구매하거나 그 가능성이 있는 구매자)를 대상으로 관계를 축적, 강화하는 활동.
CEM : Customer Experience Management 고객 경험 관리 경험 즉, 접점에서 고객이 주관적, 감성적으로 느끼는 부분을 집중 관리하는 활동. 좁게도 넓게도 개념이 사용됨. 현장에서 고객과 만나는 지점과 순간이 (Touchpoint 또는 Moment of Truth MOT로 불리는) 특히 중요하게 여겨짐.
7.1 One View One Voice System
예시) 신한은행의 One View One Voice System 고객 접점 통합 관리 체계
- 각 고객 접점에서 발생되는 정보를 통합한 One View 체제 구축(Digital Customer Experience)
- One View 체제를 통하여 고객 이동경로를 분석하고 고객 경험을 공유함으로써 One Voice 전략을 구현

7.2 Touch Point Info from App Logs
접촉 정보는 기존 Layout을 활용하도록 하되 채널별 개편된 업무를 반영하도록 코드를 재설계
접촉코드 구성체계 : 업무 접촉 범위가 가장 넓은 웹뱅킹의 메뉴 구조를 기반으로 설계함으로써 타 채널의 접촉종류를 포함할 수 있도록 함
7.3 Transaction Info from Web Logs
- 거래정보는 채널별 발생되는 거래 중 영업 또는 분석적인 활용이 가능한 거래만 엄선 적재
- 거래코드 구성체계 업무범위가 가장 넓은 영업점 업무량 분석의 업무분류를 기반으로 설계하고, 일부 타 채널에서만 발생되는 거래종류를 추가하도록 함
7.4 Integrated customer Services Platform

7.5 Customer Journey Map

7.6 Data-driven Process Mining (참고)
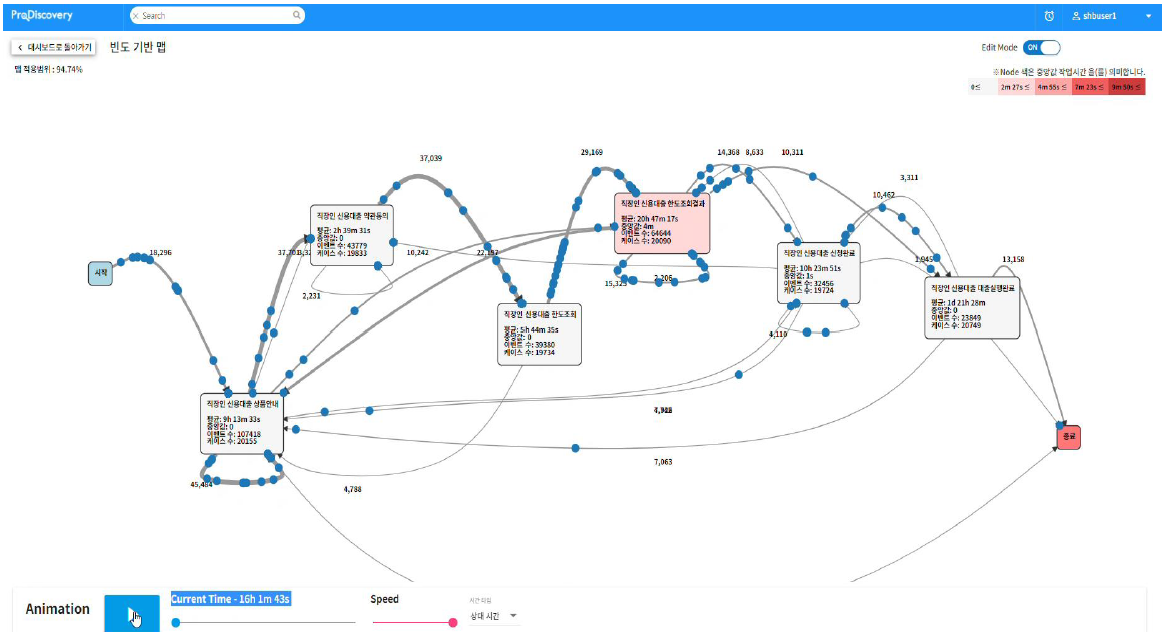
8 VOC (Voice Of Customer) / STT (Speech To Text) Analysis
"Listen to Customers and Collect Data for AI(ChatBot)"
8.1 VOC (Voice Of Customer) System

8.2 소셜 데이터 분석

8.3 VOC 대시보드
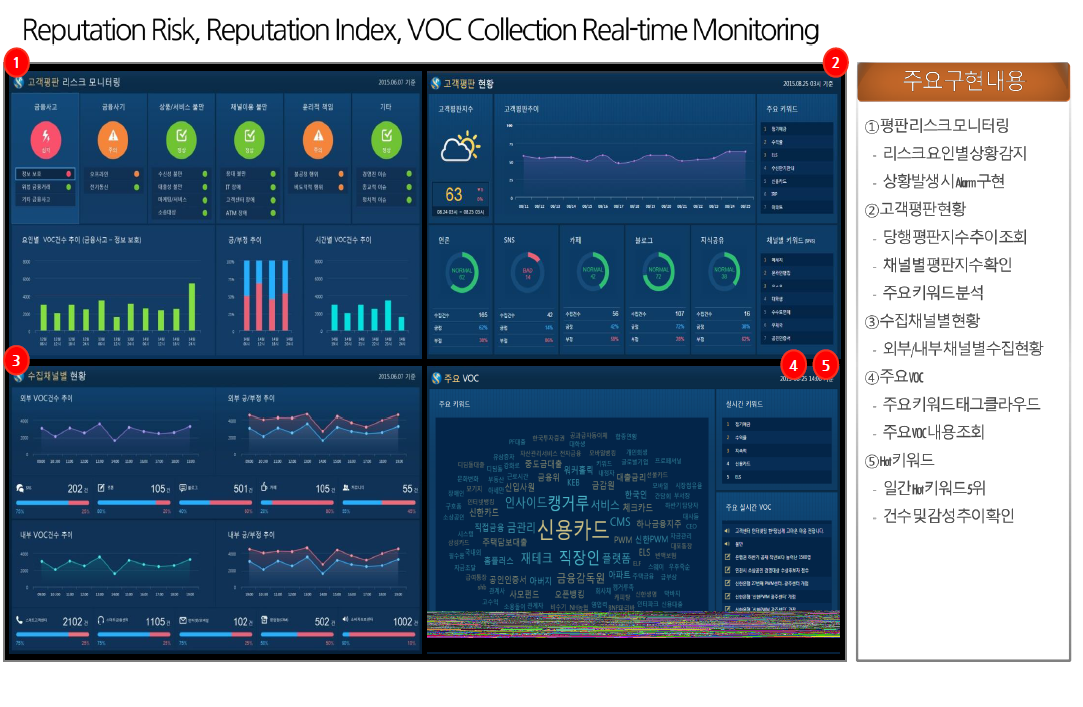
8.4 우리에 대해 많은 것을 알고 있는 x
x : twitter , meta : facebook
왜 빅테크 기업은 검색엔진을 무료로 제공할까?
현대판 헨젤과 그레텔
x는 우리를 얼마나 알고 있을까?
데이터와 친해야 하는 이유
마이데이터와 Web 1.0 , 2.0(검색엔진에서 수집하는 정보) & 3.0(공공으로 공유 혹은 블록체인으로 정보 나눔)
★ 데이터 분석보다는 데이터 활용이다! ★
9. 데이터 활용
9.1 무엇이 중요한가? 빨대? vs 마실 음료?
ex)
"김대리, 우리회사에 방대한 양의 데이터가 있어. 뭐가 나올지 모르지만 R, Python, 딥러닝 뭐 이런거로 만들어서 성과물을 가져와 봐"
★데이터 분석문제를 디자인하는 능력을 배양하는 것이 중요
1. 목적과 문제를 정의 하는 것
2. 문제를 풀기 위해 필요한 데이터를 설정하는 것
3. 그 데이터를 분석하는 것
9.2 과거의 데이터 분석 툴

9.3 기술 통계vs 추론 통계

전수조사 : 전체 다 조사함
표본 조사 : 표본만 조사함
왜 표본 조사를 하는가? -> 돈이 많이 들고 모집단 모두를 조사하는 건 불가능 함
표본을 만들었을때 표본은 모집단의 특성을 반영해야함 -> bias가 없어야함 (편차(편향)가 없어야 함)
ex) 인공지능이 샘플링 안하고 그냥 뽑는 다면 bias된 데이터가 많을 수 있음 (인종차별 등)
9.4 추론 통계의 기능

표본으로부터 모집단을 추정하는 것
9.5 통계 분석의 종류

9.6 표본 오차와 편향

Source: https://blog.naver.com/angryking/222353016734
표본 오차 : 모집단의 모수와 푶본의 통계량 간의 차이로 인해 통계치가 모수치의 주위에 분산되어 있는 정도 (표본을 추출했을 때 일반적으로 발생하는 오차임)
비 표본 오차 : 자연 발생적인 표본 오차를 제외한 오차 (결과를 왜곡 시킬 수 있는 오차)
ex) ai의 이상한 학습자료, 학습자료 부족
9.7 표본 추출에서 나타나는 편향의 종류
1. 표본추출편향(sample selection bias)
표본 추출 과정에서 체계적인 경향이 개입되어 모집단에서 편향된 표본만 추출되는 경우(ex 루즈벨트 대통령 선거 여론 조사에 전화번호부 사용)
2. 가구 편향 (household bias)
모집단의 부분 집단 단위에서 하나의 관측치 씩 추출하는 경우 크고 적은 잡단이 작고 많은 집단 보다 적게 추출되는 경우 (ex 가구의 집 전화 여론 조사시, 대가족 vs 소가족)
3. 무응답 편향 (no-response bias)
설문에 응답하지 않은 사람들과 응답하는 사람들에게 체계적인 차이가 있는 경우 (ex 지지 정당 설문)
4. 응답 편향 (response bias)
설문 형식의 문제, 응답자의 심리적 이슈에 의해 표본이 영향을 받는 경우 (ex 선거 당일 출구 조사시)
★ 데이터를 목적을 가지고 분석하는게 중요! ★
9.8 인지적 편향의 종류 (cognitive bias)
→ 분석가의 성향이나 상황에 따라 비논리적인 추론을 내리는 패턴
인지심리학자인 Amos Tversky와 행동 경제학자 Daniel kahneman이 "사람들은 언제나 합리적으로 생각하고 행동하는 것이 아니며, 휴리스틱 (heuristic : 체험적인)을 통해 왜곡된 지각으로 결정하는 경우가 많다."
1. 확증편향(confirmation bias)
자신이 본래 믿고 있는대로 정보를 선택적으로 받아들이고 임의로 판단하는 편향 (ex 본인 주위 사람들의 고정관념)
2. 기준점 편향(anchoring bias)
분석가가 가장 처음 접하는 정보에 지나치게 매몰되는 편향 (ex 가격 흥정)
3. 선택 지원 편향(choice-supportive bias)
확증편향과 유사한 개념으로 본인이 의사결정을 내리는 순간 그 선택의 긍정적인 부분에 대해 더 많이 생각하고 그 결정에 반대되는 증거를 무시하게 되는 편향
4. 분모 편향 (denominator bias)
분수 전체가 아닌 분자에만 집중하여 현황을 왜곡하여 판단하는 편향 (ex 안록산의 난 vs 2차 세계대전 인구의 15% vs 4% 실제로 사망자 1.3천만명 vs 1억명)
5. 생존자 편향(survivorship bias)
소수의 성공한 사례를 일반화된 것으로 인식함으로써 나타나는 편향
아래는 생존자 편향의 예시
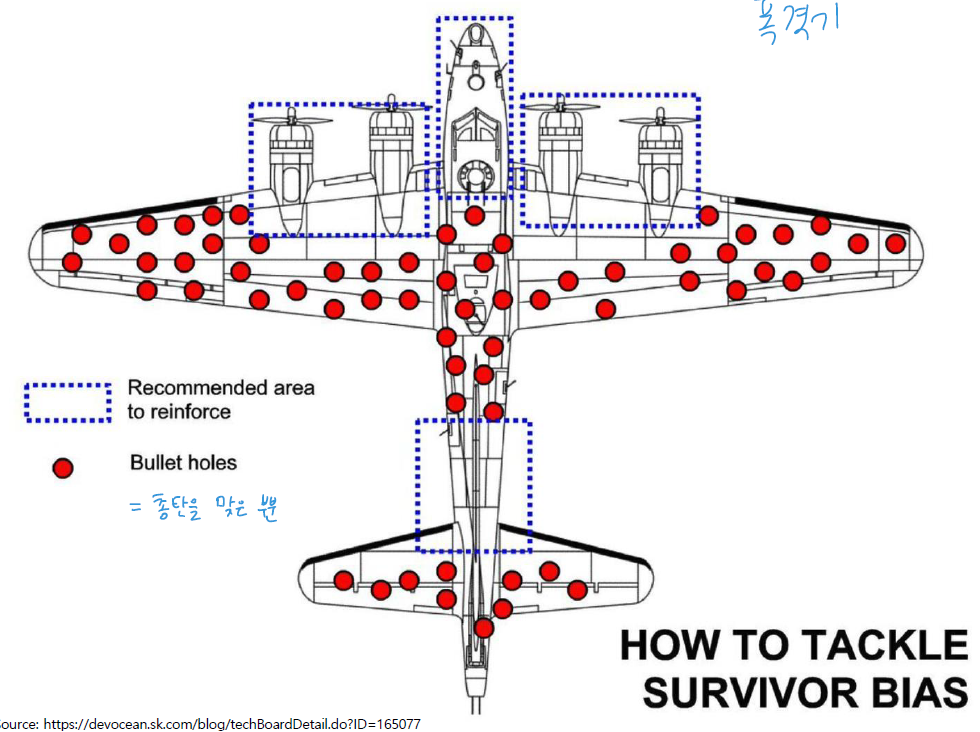
→이미 살아남은 폭격기들이 엔진과 조종하는 부분을 안 맞았기 때문에 살아남음
미해군이 고용한 통계학자 “아브라함 왈드(Abraham Wald)”는 다른 사람들과 다른 의견을 제시합니다.
귀환율을 높이려면 “비행기 머리부분인 조종석과 엔진의 장갑을 더 두껍게 하고 튼튼하게 해야 한다”고 주장한 것입니다. 그는 근거를 말했습니다.
“날개와 몸통에 총탄을 맞은 비행기들은 어찌됐든 귀환해 우리 눈앞에 있습니다. 하지만 조종석과 엔진을 피격당한 비행기들은 돌아오지 못했습니다.
조종석과 엔진 부분에 빨간점이 없는 이유는 그 부분을 피격당한 전투기들이 귀환하지 못했다는 강력한 증거입니다.”
9.9 데이터 활용의 기초 사고력
- 인공지능도 학습이 필요하고 학습에 필요한 것은 바로 데이터
- 강아지 밥주듯이 로봇에게 데이터만 준다고 해결되는 것은 아님
- 인공지능 로봇을 부려먹으면서 편하게 살려면 어떤 능력이나 기술이 필요할까?
- 인공지능을 설계하고 기술을 활용하기 위해 이미 우리 안에 내재된 강력한 사고력이 필요!
9.10 AI가 우리 일자리를 대체할까?
1. 새로운 기술에 의한 일자리 변화로 갈등이 생김
ex1 붉은 깃발법
ex2 여객 자동차 운수사업법, 플랫폼 운송사업과 택시 사업자간의 갈등 ex) 카카오 택시, 타다
2. 자율 주행차의 발달로 바라본 일자리 변화
-인공지능은 우리를 위험하고 힘든 일에서 해방시켜 줄 것임
-밥도 먹지 않고 잠도 자지 않는 인공지능과 경쟁하지 않아야 함
3. 미래 사회의 일자리
- 인공지능과 협력하는 일자리: 충분한 데이터가 없는 분야, 사람의 섬세한 동작과 손실이 필요한 분야
- 인공지능을 설계하고 활용하는 일자리: 컴퓨터가 사고하는 방식을 이해하고 창조적으로 설계, 분야간 연결하는 능력이 필요한 분야 ->즉 MR : machine-readable처럼 ai가 편하게 학습할 수 있도록 하는 data를 만들어주는 등의 일
9.10 인공지능을 부려먹는 역량
컴퓨팅 사고력이란?
과학자뿐만 아니라 모든 사람이 갖추어야하는 기본적인 역량이다.
9.11 컴퓨팅 사고력(Computational Thinking)의 4가지 구성요소
1. 분해 (decomposition) =모듈화
복잡한 문제나 시스템을 적절한 크기로 쪼개고 해체하는 작업
2. 패턴인식(pattern recognition)
다양하고 복잡한 현상 및 정보 속에서 유사성, 인간관계 등 질서 파악
3. 추상화 (Abstraction) =일반화
불필요한 디테일을 제외, 핵심적인 정보를 간추려 내는 단계
4. 알고리즘화(Algorithms)
파악된 문제를 해결하기 위해 단계적인 솔루선을 설계하는 작업

'학교 > 데이터와 정보세계' 카테고리의 다른 글
| [Data & Information Society] 데이터와 정보세계 7 (0) | 2024.04.22 |
|---|---|
| [Data & Information Society] 데이터와 정보세계 2 (1) | 2024.04.22 |
| [Data & Information Society] 데이터와 정보세계 5 (0) | 2024.04.20 |
| [Data & Information Society] 데이터와 정보세계 4 (0) | 2024.04.20 |